PSYC 210 Lecture Notes - Lecture 11: List Of Statistical Packages, Standard Deviation, Scatter Plot

20 Nov 2017
School
Department
Course
Professor
Document Summary
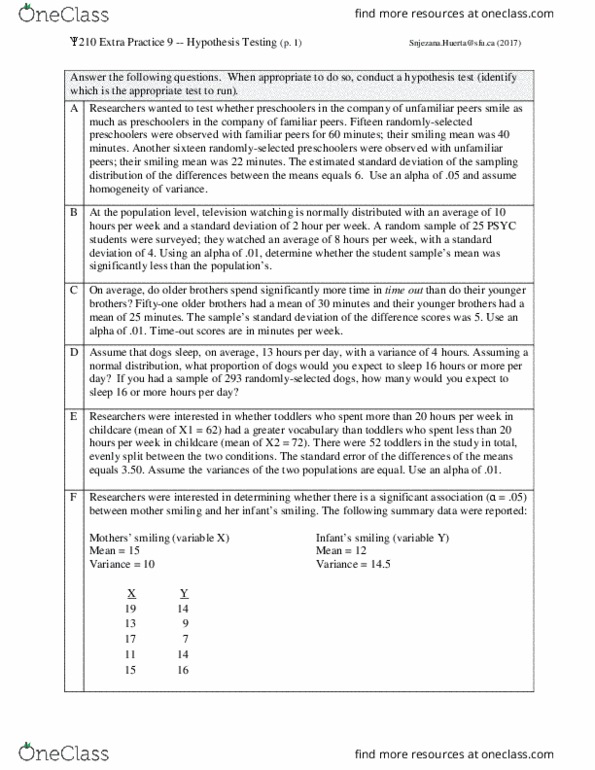
Please submit on time to avoid late penalties. **see overall instructions in canvas (in announcement and on assignment page)** answer in order, show work, draw graphs yourself, provide explanations, use own words, cite, no plagiarism, no statistical software. - p. 1 -- round probabilities to the thousandths in your final answers. [2 points] in your own words, explain the connection between the relative frequencies that represent a set of scores and the probabilities that are based on them. [3 points] imagine we surveyed 64 people, whom we asked to indicate how happy they were with their dentist; the relative frequencies of the 8 possible responses are tabled below. [2 points] imagine that 36% of our population didn"t work at all on january 1 and 42% of the population worked a longer shift than usual to accommodate others taking the day off. [4 points] assuming a population of 11,605 x scores that are normally distributed with a mean of.