STAT151 Lecture Notes - Confounding, Total Variation, The Bs

7 Mar 2014
School
Department
Course
Professor


4
STAT151 Full Course Notes
Verified Note
4 documents
Document Summary
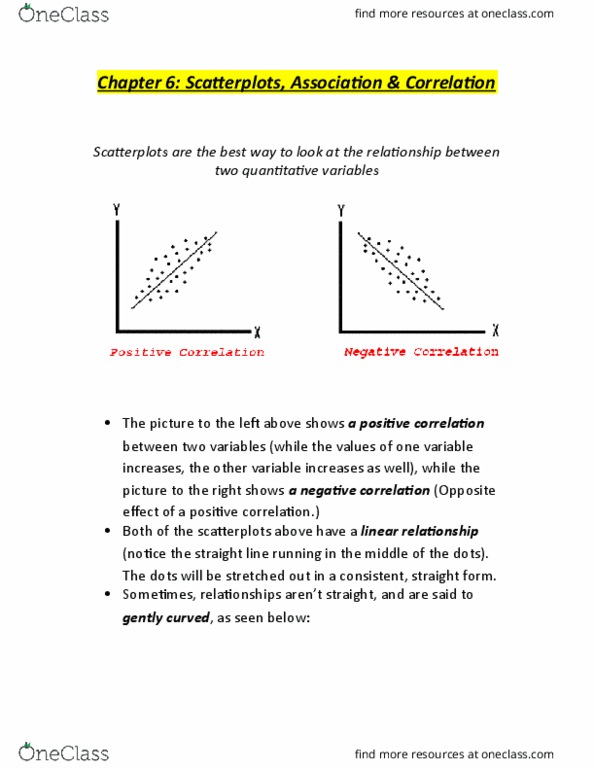
We will be investigating the relationship and association between two quantitative variables (bivariate data), such as height and weight, the concentration of an injected drug and heart rate, or the consumption level of some nutrient and weight gain. Sometimes the purpose of a study is to show that one variable can explain the outcome of another variable. Response (or dependent) variable (symbol: y) - measures an outcome of a study. Explanatory (or independent) variable (symbol: x) explains or causes changes in the response variable. We measure x and y for each individual. Observations are recorded in the form (x, y) Our sample of n bivariate observations is (x1, y1), (x2, y2), , (xn, yn) Scatterplot is the best way to start observing the relationship and the ideal way to picture associations between two quantitative variables is a plot of pairs of observed values of two different quantitative variables. It helps to evaluate the quality of the relationship.