🏷️ LIMITED TIME OFFER: GET 20% OFF GRADE+ YEARLY SUBSCRIPTION →
Pricing
Log in
Sign up
Home
Homework Help
Study Guides
Class Notes
Textbook Notes
Textbook Solutions
Booster Classes
Blog
Home
Class Notes
1,200,000
CA
670,000
STAB22H3 Lecture Notes - Adirondack Mountains, Scatter Plot, Substance Abuse
36
views
17
pages
ochreprairie-dog300
24 Nov 2012
School
UTSC
Department
Statistics
Course
STAB22H3
Professor
Ken Butler
Like
For unlimited access to Class Notes, a
Class+
subscription is required.
armindivansalar
and
39413 others
unlocked
38
STAB22H3 Full Course Notes
Verified Note
38 documents
Get access
Yearly
Monthly
Yearly
Grade+
20% off
$8
USD/m
$10 USD/m
Billed $96 USD annually
Homework Help
Study Guides
Textbook Solutions
Class Notes
Textbook Notes
Booster Class
40 Verified Answers
Class+
$8
USD/m
Billed $96 USD annually
Homework Help
Study Guides
Textbook Solutions
Class Notes
Textbook Notes
Booster Class
30 Verified Answers
Continue
Related Documents
STAB22H3 Lecture Notes - 2G, Scatter Plot, Probability Plot
ochreprairie-dog300
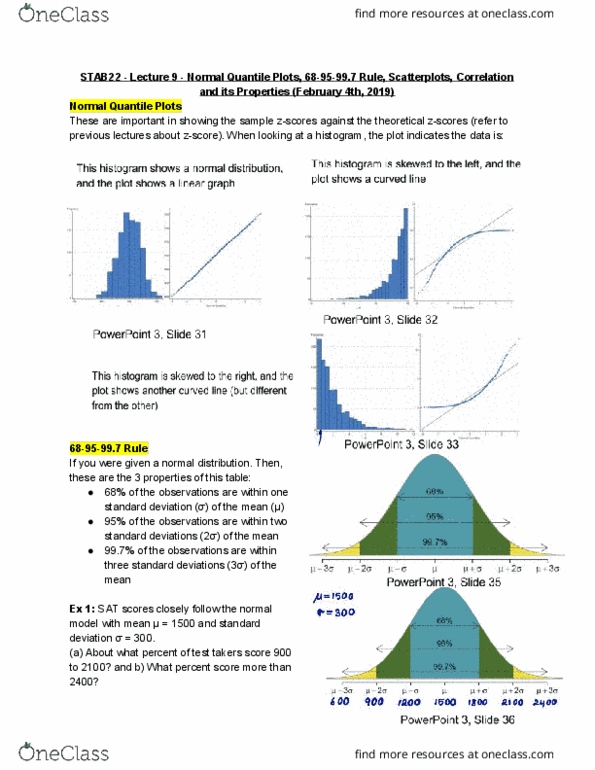
STAB22H3 Lecture 9: Normal Quantile Plots, 68-95-99.7 Rule, Scatterplots, Correlation and it's Properties
karishkobal
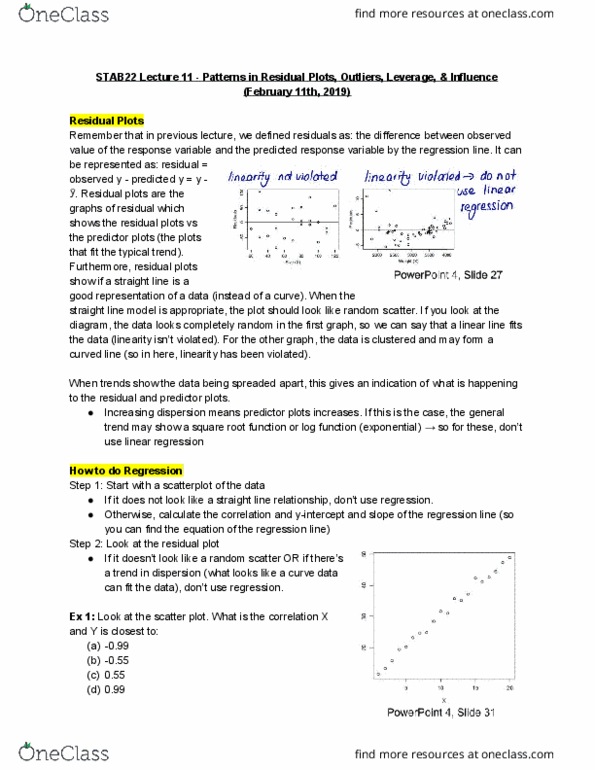
STAB22H3 Lecture 11: Patterns in Residual Plots, Outliers, Leverage, & Influence
karishkobal