SOC280 Study Guide - Midterm Guide: Repeated Measures Design, Sampling Distribution, Standard Deviation

7 Nov 2013
School
Department
Course
Professor

Document Summary
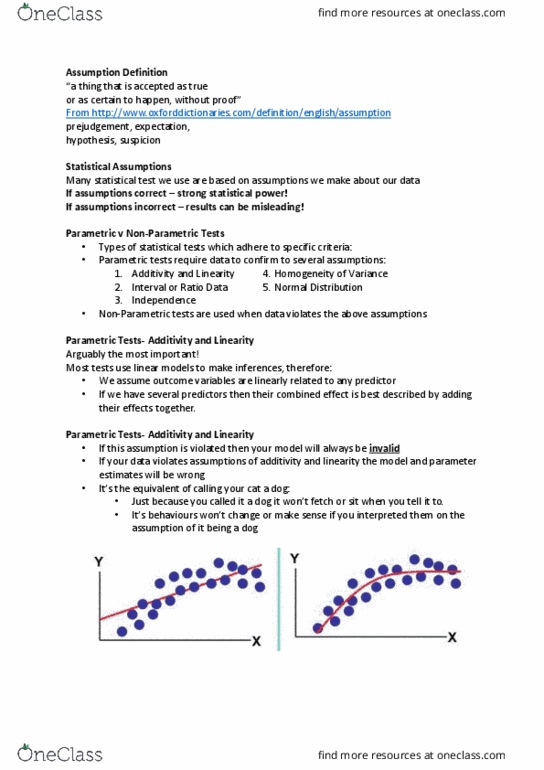
Assumptions are critical because if they are broken, we stop being able to draw accurate conclusions about reality. Parametric test is based on normal distribution, requires data from one large catalogue of distributions, assumptions need to be met in order for data to be considered parametric. Most parametric tests have four assumptions that need to be met: normally distributed data. Data should be normally distributed, whether it"s the sampling distribution, or the errors in the model, or something else) If it is not met, the logic behind the hypothesis is flawed: homogeneity of variance. Variances should be the same throughout the data. In correlational designs, this means that the variance of one variable should be stable at all levels of the other variable. In designs where you test several different groups, each sample comes from populations with the same variance. Ordinals can be faked as intervals if there is enough of them.