BUSI 1450U Study Guide - Midterm Guide: Random Variable, Simple Random Sample, Statistic


Document Summary
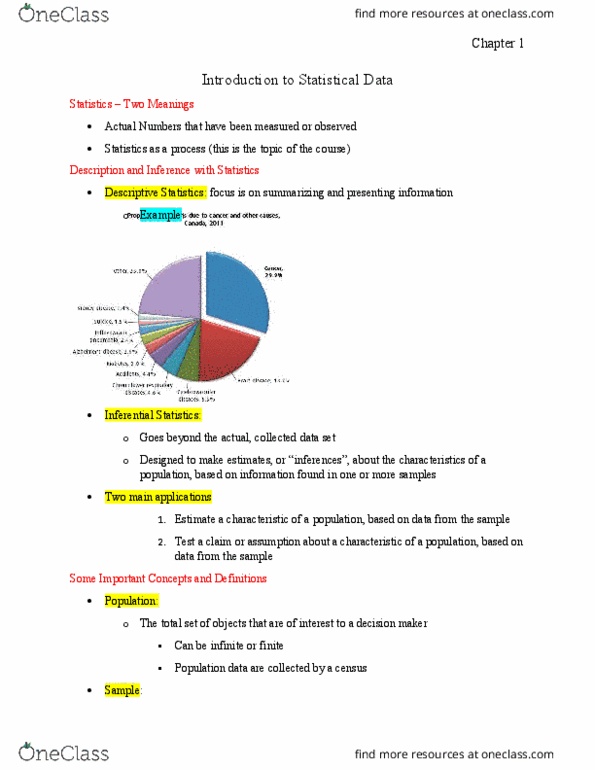
Statistics can be defined as the art of collecting, classifying, interpreting, reporting numerical information related to a particular subject. Population the total set of objects or measurements that are of interest to a decision maker. Descriptive statistics focused on summarizing and presenting information. Such as pie graphs, bar graph, etc comparing populations of different provinces. Data set the set of all observations for a given project or purpose. Inferential statistics goes beyond the data asset that is at hand. Designed for making estimates, or interferences, about the characteristics of a population, based on information found in one or more samples. Two main types of problems call for inferential statistics: estimate a characteristic of a population, based on data from a sample, example: survey finds that 52% of questioned voters support a certain piece of legislation. A survey finds that 52% of questioned voters support that legislation.