MBG 2040 Chapter Notes - Chapter 12: Start Codon, Peptide, Transfer Rna

25 Nov 2012
School
Department
Course
Professor
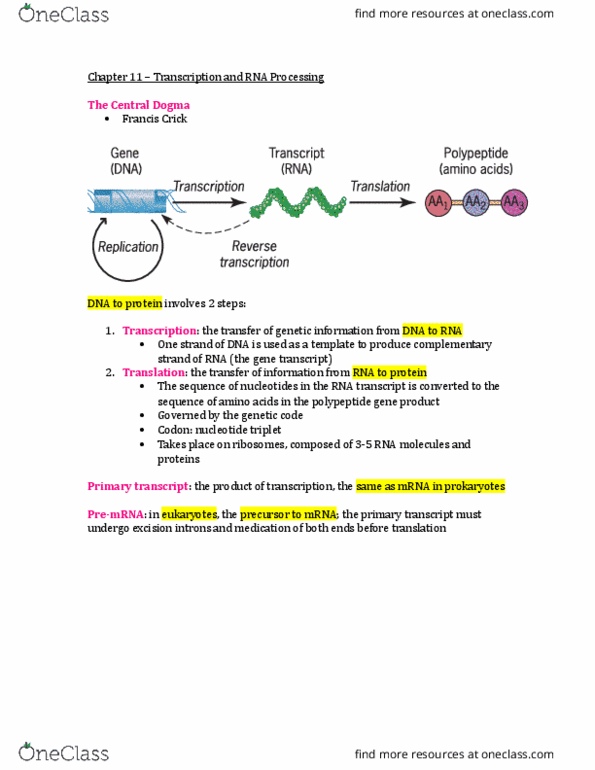
Document Summary
An overview: the genetic code is composed of nucleotide triplets. Three nucleotides in mrna specify one amino acid in the polypeptide product; thus, each codon contains three nucleotides: the genetic code is non-overlapping. Each nucleotide in mrna belongs to just one codon except in rare cases where genes overlap and a nucleotide sequence is read in two different reading frames: the genetic code is comma-free. There are no commas or other forms of punctuation within the coding regions of mrna molecules. During translation, the codons are read consecutively: the genetic code is degenerate. All but two of the amino acids are specified by more than one codon. Complete degeneracy: the third base can be changed to anything and will still encode same aa. Partial degeneracy: when the 3rd base may be either of the two pyrimidines (u or c) or, alternatively either of the two purines (a or g).