BIOD08H3 Lecture Notes - Lecture 7: Computational Neuroscience, Linear Separability, Sigmoid Function

11 Nov 2019
School
Department
Course
Professor

Lecture 08 Deep Learning
[slide 1]
Deep learning is actually a very board research program which has a root in computational neuroscience, that has now started to
influence neuroscience again with its impact on the neuroscience is increasing exponentially

[slide 2]
How do we optimize a neural network? This is going to be the perspectives of how we are going to investigate deep learning, in
which we have already started talking about it last week
Recalling from last week, while the synaptic plasticity and memory hypothesis (abbrev: spm hypothesis) has been generally accepted
in the field
• Our ability of learning and remembering things is fundamentally the result of the ability in changing the synaptic connections
between the neurons, in order to alter the way the information is flowing through the circuits
The way that we are going to frame this problem of how the synaptic connections are being altered in order to learn something, is
through defining a loss function
• Loss function, is simply saying how badly you are doing something, which can be any function that measures the badness
• While the goal of the learning agent, is to minimize the loss in order to maximize the learning.
• Mathematically, it means we are interested in finding the synapses weights, W*, that provide the minimal amount of loss
• At the minimum, learning has to involved the improvement of the minimization of the loss function, meaning overtime, the loss
must goes down
o This is being expressed through the expression with time t using the loss function L

[slide 3]
However, the problem that we face is that we have a stupidly large number of synapses, hence how are we going to update the
information?
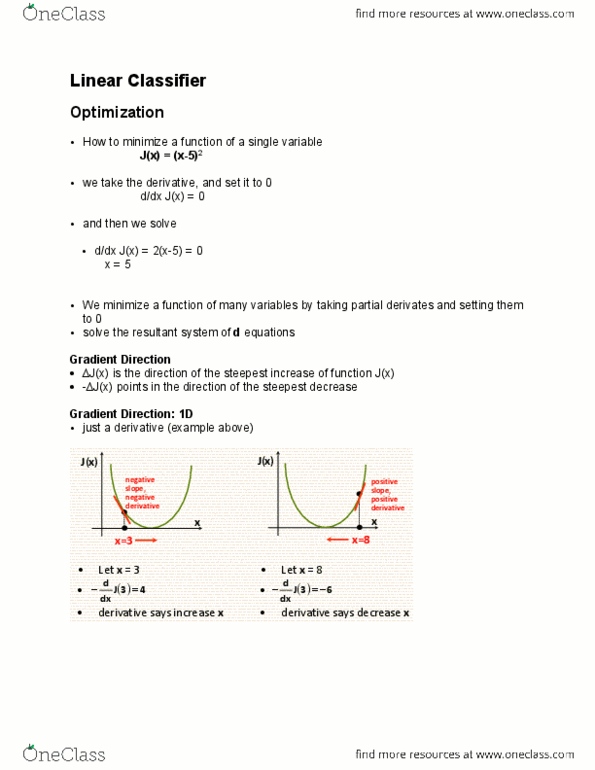
Recalling the algorithm being taught is gradient descent
• Gradient decent, basically expressing the loss function is the function of the synaptic weights (x-axis), and y-axis the Loss
function
• We are going to update the gradient by going down the gradient of this loss function — meaning we are going to determine the
slope of the function, and whatever the slope of the function is decreases, that would be the direction we are going for
• One important thing to keep in mind is that these updates needed to be done in small steps because you can image that if you
have a function that
o For example, if the slope in this particular synaptic weight is telling us that it is decreasing, thus going in the right
direction. However if you go too far in the next step, you are going to jump to the other side of the function
o This is why the variable α, is being introduced, that is responsible in the controlling of the step sizes
• As W becomes W- the slope of the loss function multiplied by α