BIO120H1 Lecture : BIO 240 notes.doc



36
BIO120H1 Full Course Notes
Verified Note
36 documents
Document Summary
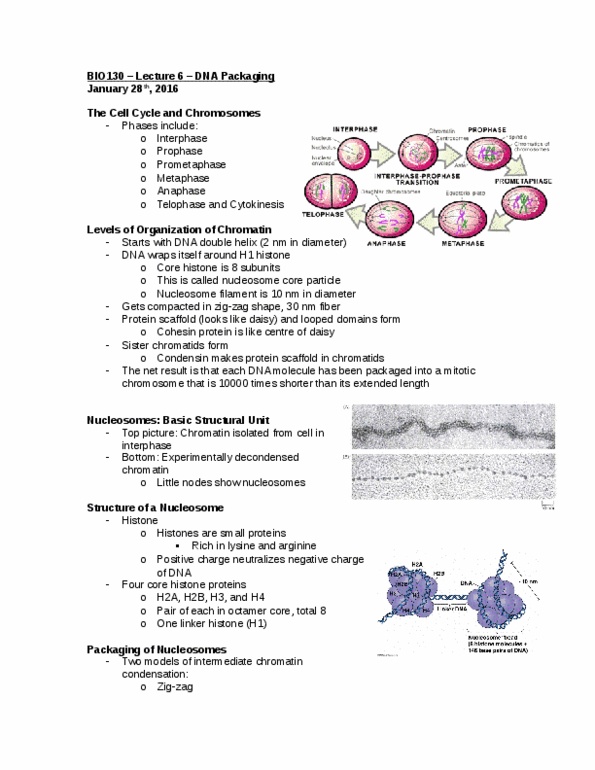
In eukaryotes protein-coding genes are usually composed of a string of alternating introns and exons associated with regulartory regions of dna: cells contain dozens of different atp-dependent chromatin remodeling complexes which are specialized for different roles. The dna in eucaryotes is tightly bound to an equal mass of histones, which form repeated arrays of dna-protein particles called nucleosomes. The nucleosome is com-posed of an octameric core of histone proteins around which the dna double helix is wrapped. Nucleosomes are spaced at interuals of about 200 nucleotide pairs, and they are usually packed together (with the aid of histone hl molecules) into quasi-regular arrays to form a 30-nm chromatin fiber. Despite the high degree of compaction in chromatin, its structure must be highly dynamic to allow access to the dna. There is some spontaneous dna unwrapping and rewrapping in the nucleosome itself; how" euer, the general strategy for reuersibly changing local chromatin structure features atp-driuen chromatin remodeling complexes.